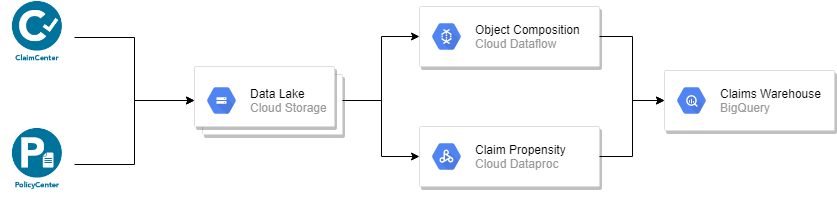
Enabling Looker Access to GCP Hosted Database
If you’re hosting Content Manager on the Google Cloud Platform, you’ll need to whitelist various IP addresses. Doing so will enable Looker to query the metadata repository for Content Manager and gives LookML developers the ability to build looks based on the CM schema. Note that this bypasses the built-in CM security model, but that’s OK if you understand the risks. If you’re a SOC compliant organization you can mitigate this by layering in compliance processes to monitor this access.
If you visit the Looker support site you’ll find this article that defines how to enable secure database access. To implement you need to visit the Cloud SQL instance connection page and add in the IP addresses. Note that you need the “/32” at the end of each address to denote it’s a single IP range.

That’s all you need to do! Now Looker will be able to connect to your CM database!