Piggy-backing a Modern Analytics Architecture
Let’s say you’re one of the many Federal Agencies, Regulated Industries, or State & Local Governments migrating their analytical infrastructure onto the secured GCP platform (those ISO 27001, ISO 27017, ISO 27018, FedRAMP, HIPAA, and GDPR certifications make this a no brainer!). You will soon have access to tools and advanced capabilities that will enable a more comprehensive usage of Content Manager’s audit, compliance, and governance features. More importantly, you can start leveraging technological investments driven by departments & cost centers that have significantly higher budgets than you may have in your Records Management Office.
Consider this simple architectural pattern:
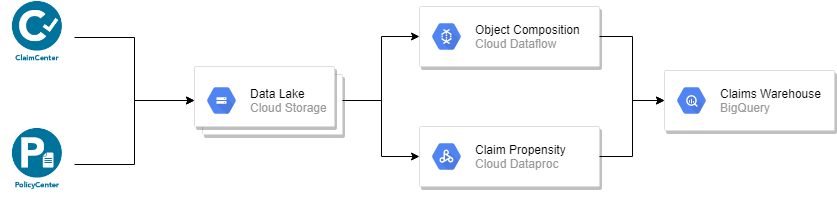
I’m actively working with two large insurance companies that are in the process of implementing this exact architecture. For each of them it’s a multi-year, multi-million dollar, multi-department modernization effort that will both migrate their analytical infrastructure and transform how they work. There are far more components in their final architecture, but I’ve simplified the diagram to make things more clear in this blog post.
I find it exciting that both customers agreed that governance was one (of many) priority logical capabilities. To them, initially, governance is primarily focused on data quality, master data, loss prevention, and security. Content Manager brings a lot to the governance table though. By piggy-backing the analytical infrastructure we can leverage existing investments and tap into entirely new technologies. All we need to do is think outside of the on-premise mental box.
Regulatory Compliance Use Cases
Two key aspects of regulatory compliance are records management and business process integration. Once you move into a modern analytical architecture though, you no longer need to directly integrate Content Manager with the source systems. Now you can tap into data as it flows through the architecture.
Using a SaaS product hosted on AWS that publishes to a Kinesis stream? Not a problem! We can use a Lambda to immediately create a record in Content Manager so that compliance officers have immediate access to records!

Or maybe you want to ensure record holds are annotated in the Warehouse in real-time? Also, not a problem! Apache Beam, the open-source framework backing Dataflow, makes it easy to pull in active record holds as a side input via the CM Service API.

Or maybe you need to push Content Manager data into your environment so that you can mitigate operational risk by extracting entities & sentiment from textual underwriting notes (stored in CM)? GCP makes it simple! We just need to create a Cloud Composer DAG that pulls the content from CM, runs them through AutoML, submits a job to an auto-provisioned Hadoop cluster, run the PySpark model to predict the propensity a new policy will file a claim, submit the results to BigQuery for retrospective analysis, and automatically kick-off workflows for internal auditors to evaluate a random sampling of the model results!

By just cobbling components together we can leverage the existing investment in the analytical infrastructure to create compelling Content Manager integrations that drive regulatory compliance. This can be a compelling low-code approach that delivers immediate results from your cloud investment. Just scratching the surface with the exciting things on the horizon!